
As I sit in my office, on March 16 I will have the odd honor of celebrating one year of doing business submerged in the corona virus crisis. I cannot speak openly about business matters of the company I work for, but I can say we correctly managed and sailed the murky waters of the disaster executing the right moves. We learned many lessons from the outcome. The one lesson I hold now dear is that this is not over, and that many people incorrectly think it is.
The world will move on (the world always does.) But the world moving on is not synonymous with the world returning to normal. Things will not go back to normal, and those incapable of assimilating this notion are doomed to fail or fall short of their expectations.
For starters, the COVID-19 is probably one of many black swan events sure to occur in the nearby future. The virus surprised everyone but epidemiologists around the world who had been warning about such an event for almost a decade now. The world has now over seven billion people. The number is putting stress on our environment, and surely we passed the line of how many is the right number of people to inhabit the land long ago. It’s only natural that under the actual scenario of climate change, overpopulation, depletion of resources, and general attitude to kick the problems forward for some future generation that might care, natural black events such as disease, pandemics, weather phenomena, and the like will play havoc with our lifestyle.
For those young enough to start a life, I would suggest sticking to a minimalistic one. There are plenty of videos on the web on how a minimalistic approach can lead to great results. I am guilty of not following that same advice, which further complicates my decision making process. For those like me sooner to retire than not, it represents a great opportunity to cut our losses short and retire to a more modest, but in no way less fulfilling life. For those stuck in the middle, it gets more complicated.
The economies of Latin America won’t pick speed for the next five years or so. Sure, big corporations will make the most of the situation and regain lost market share and revenue fast. But big corporations are not the other 99% of Latin America. Big corporations are not even the other 99% of workers and executives working for them, many who are either furloughed, lost their jobs, or are taking on more work and less pay just to keep afloat.
The demand for anything is less. The demand for food is less. The demand for leisure is less. The demand for clothes, shoes, computers, furniture, everything is less. Yes, some things sold-out. PS5 and new XBox sold-out. But I wonder how many units were produced versus the pandemic forecast. I have reduced inventories far below the recommended level, adjusted for pandemics and then some, to balance imperfections between demand and supply. I have seen a similar pattern in iPhone 12 except for the mini, which Apple produced in quantities to cater the voices of thousands of consumers who then rushed to buy normal and plus sizes, proving consumer sentiment analysis is anything but a fickle art even when using sophisticated AI techniques.
In the future access to credit will be restricted, but I would warn anyone to use leverage as a way to kickstart a business. If the crisis taught us anything, it is that leveraged operations were the first to fall. In the early beginning of the pandemic everyone agreed cash flow was king and that cash accounts were the vehicle to survival. For those employed or freelancing, I would recommend going out of their way to save 12 months (yes, twelve, not eight as everyone else has proposed before) of expenditure for emergency funds. It is a large sum, none the less one that might be in need given the extension of the pandemic and future black events.
That is a perfect segway for my next thought: any business should start without leverage and be capable of monthly flows with return on investment from day one. That is a nearly impossible objective, yet a lot of people survived thanks to rapidly shifting focus, and assessing a new operations model.This is not just small business but what I call survival business: the girl who I hardly know but uses her small, low-cost Kiah Picanto to deliver food on weekends from restaurants at U$2.50 a trip, or the service person for A/C units who was furloughed but kept a good database of customers who like me resorted to tertiary assistance in order to maintain the apartment infrastructure going while in lockdown. They made do with whatever they had to generate cash flow immediately, maybe not enough, but certainly more than nothing.
Can you make your business model black swan proof? Can anyone make their business model resilient enough to guarantee operations despite weather events, pandemics, wars, disruption of services such as web, wireless, etc.? I doubt anyone can, but at least we can take measures to minimize the effect. I think retail has a long way to go before expansion of brick and mortar, and probably expansion of brick and mortar should be ditched altogether for a fully digital model. The bad thing about this is retail is a good contractor of people, people who do not make much but certainly make more than unemployed ones. Digital business only hires at the top (programmers and engineers who have the job cut out for them and will probably thrive) and the bottom (low wage fulfillment center workers toiling in a warehouse dispatching boxes, or the drivers that accompany the movement.)
Ghost kitchens probably fared better than restaurants in the pandemic, and I know this to be a fact in Panama. Ghost kitchens however lost revenue to the hundreds or thousands of people furloughed or fired, who turned to the Internet, social media, and their friends, offering food service of all kinds: desserts, sandwiches, pizzas, and many more amenities of the cuisine world. The consumer is probably used to delivery and staying at home and will shy away from restaurants for a long time. Some might not even have the money to do so even if they wanted. I suspect young people will leave the house for bars and food before anyone else, since they are the ones to sustain the least chance of contagion in the next months before full vaccination, and, well, they are young.
The labor climate is tricky. Thousands of young people will enter the workforce soon and compete for whatever little positions are left in a world of economic recession fiercely. People such as myself will have to fight peers thirty years younger, who are willing to work more hours for a fraction of the cost. Companies will push for such a change, inviting older executives to move from salaried to freelance work. Many will revolt at the idea but I would indicate this is not a bad move, since those with significant skills, knowledge and experience will make a substantial living working less hours and securing a place in their companies because others actually need them. It creates a necessity of service without the actual friction of competing inside the corporate structure.
Inside corporations, and outside for those working on their own, the trinity of credit, risk, and cash flow will become the foundation stone of operations. We can no longer bear the uncertainty of risk unless there is sufficient free cash flow to fund such activities without major impacts to one’s financial position. We can no longer bear credit to leverage operations that could go months on end without revenue and thus be asphyxiated by debt. And we can no longer bear operations that don’t return frequent inflows of cash to sustain a non-leveraged operation desperate for sources of income.
In resume, avoiding credit, bootstrapping for low-risk business models that quickly generate sources of revenue is the way of the next five years. And should black swan events become more prevalent, the way for the next decade or more.

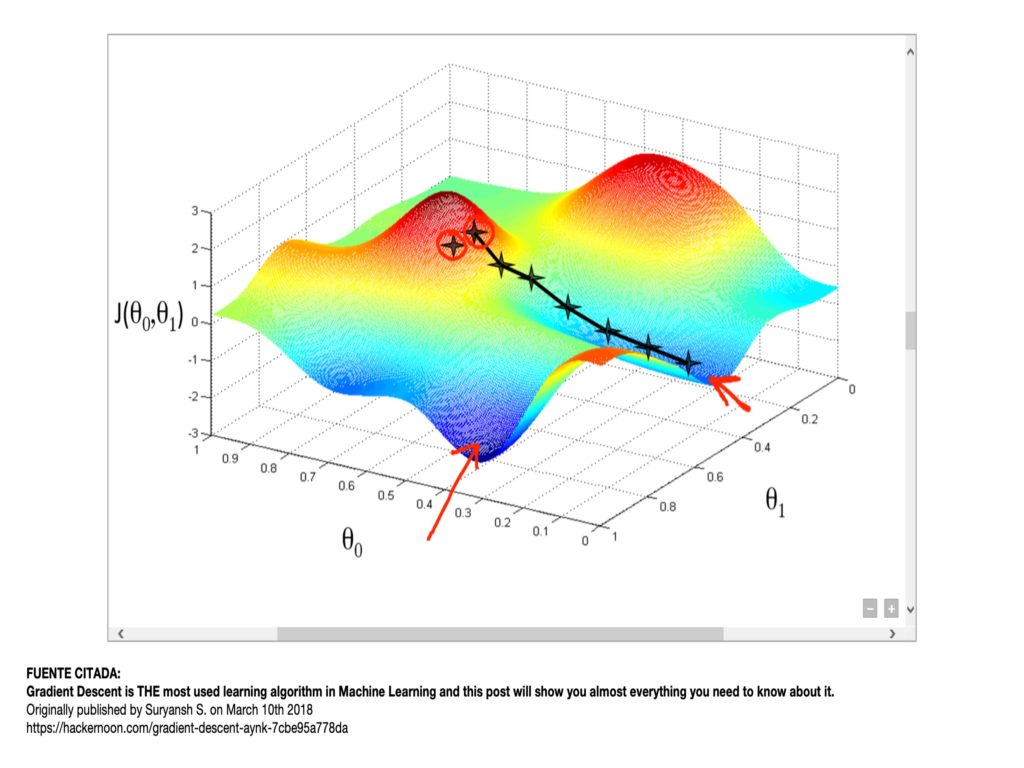

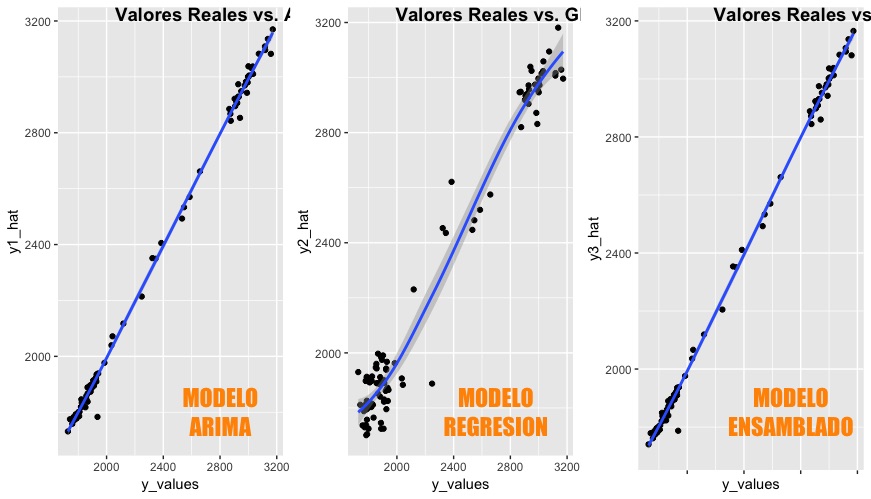







 There is a danger inherent to sales teams and salespeople everywhere: overloading. Overloading is evil, but its effects, despite usually short-term, do not seem to affect sales teams, who will soon oversell and overload the market with despicable effect.
There is a danger inherent to sales teams and salespeople everywhere: overloading. Overloading is evil, but its effects, despite usually short-term, do not seem to affect sales teams, who will soon oversell and overload the market with despicable effect.