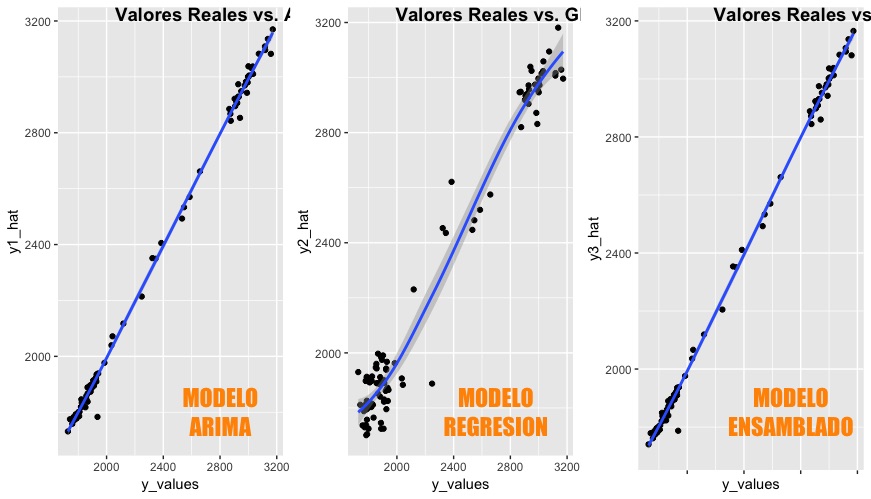
I recently worked with 3 machine learning models for FOREX prediction. One was ARIMA, the next multivariable linear regression, and the last one a stacked model that used the outputs of the first two as learners for input.
Here are the results from each:
While the regression model has an R2 value of 0.9714, the ARIMA beat it with a far better R2 value of 0.9976. That did not strike me odd, as in econometric time series analysis usually proves far more precise. But the stacked model only fared slightly better with an R2 value of 0.9978. I was expecting a little more precision out of the stacked model as it should have preprocessed and worked out the wrinkles and inefficiencies of the first two.
The topic of study is the TRM, Colombia’s official exchange rate for the US dollar. Economists and financiers have been trying to predict FOREX values since ever (or at least a very long time…) I was not looking for a break-through formula, but just something that would improve our company’s cost accounting accuracy and our ability to hedge currency volatility through forwards.
But I digress. The musing here is the additional overhead of the stacked model vs. a simple ARIMA forecast (using the excellent library by Robert Hyndmann here.) The accuracy is welcomed because when dealing with money every bit of a penny counts. But the production model is complicated at least. In my company, there is no such thing as a machine learning production model. Our IT staff is A+, but not very math-savvy. Any machine learning code is done by me, with little hope of moving it to production (and in my company it makes sense, we are small.) If a bigger enterprise how much more precision is worth the cost of additional computing cycles? The application of machine learning to ARIMA is not necessarily complicated. But having to run multiple models to ensemble does require additional computing power.
In a practical world, the difference between models is only 0.002. If the TRM is at 3,450 pesos to a dollar, the difference is 0.69 cents per dollar or 690,000 pesos in a one-million-dollar contract. That is the equivalent of 200 US dollars in one-million, which is money none the less but not a lot.
There is no right or wrong here. Since I cannot deploy my fancy algorithms to production I have not an easy way of estimating costs. But the musing is still interesting, and the simplicity of the model formulation has an incredible amount of complexity when brought to life.
The following notes are from the COURSERA Practical Machine Learning course and are intended to help others understand the concepts and code behind the math. The basic idea behind boosting is to take lots of possibly weak predictors, then weigh them and add them up, thus getting a stronger one. We could see two clear steps:
Start with a set of classifiers (h1, h2, …, hn). For example, these could be all possible trees, all possible regressions, etc.
Create a classifier that combines classification functions
Several things we want to obtain with this process:
The goal is to minimize error (on the training set)
Iteratively, select one h at each step
Calculate weights based on errors
Up weight missed classifications and select next h
The most famous boosting algorithm is ADAboost.
Boosting in R
Boosting in R can be used with any subset of classifiers. One large subclass of boosting is gradient boosting. R has multiple libraries for boosting. The differences include the choice of basic classification function and combination rules.
gbm: boosting with trees
mboost: model based boosting
ada: statistical boosting based on additive logistic regression
gamBoost: for boosting generalized additive models
Most of these are already included in the caret package, making the implementation relatively easy.
Boosting Example
For our boosting example, we will use the ISLR package and the Wage data set included. The idea here is to try to predict wage based on the many other predictors included.
# Create training and testing sets
wage <- subset(Wage, select = -c(logwage))
inTrain <- createDataPartition(y = wage$wage, p = 0.7, list = FALSE)
training <- wage[inTrain, ]
testing <- wage[-inTrain, ]
Now that we have our data we can create training and testing sets. For the problem at hand, there is no pre-processing of the data necessary, but for other types of prediction models, such as regression, some pre-processing is required for non-numerical values or variables with no variability because of the predominance of zero values.
# Create training and testing sets
wage <- subset(Wage, select = -c(logwage))
inTrain <- createDataPartition(y = wage$wage, p = 0.7, list = FALSE)
training <- wage[inTrain, ]
testing <- wage[-inTrain, ]
Fitting a boosting model in R using the caret package is very easy. The syntax is much like any other for training a data set, just include the option method = “gbm” in the option line.
# Fit a model using boosting
modFit <- train(wage ~ ., method = "gbm", data = training, verbose = FALSE)
print(modFit)
## Stochastic Gradient Boosting
##
## 2102 samples
## 10 predictor
##
## No pre-processing
## Resampling: Bootstrapped (25 reps)
## Summary of sample sizes: 2102, 2102, 2102, 2102, 2102, 2102, ...
## Resampling results across tuning parameters:
##
## interaction.depth n.trees RMSE Rsquared
## 1 50 34.39326 0.3213741
## 1 100 33.85476 0.3322011
## 1 150 33.79401 0.3341418
## 2 50 33.85892 0.3324366
## 2 100 33.77240 0.3351736
## 2 150 33.87053 0.3330873
## 3 50 33.73768 0.3365461
## 3 100 33.89518 0.3324402
## 3 150 34.09446 0.3263083
##
## Tuning parameter 'shrinkage' was held constant at a value of 0.1
##
## Tuning parameter 'n.minobsinnode' was held constant at a value of 10
## RMSE was used to select the optimal model using the smallest value.
## The final values used for the model were n.trees = 50, interaction.depth
## = 3, shrinkage = 0.1 and n.minobsinnode = 10.
Word of caution, boosting takes a little more of processing time in some computers, so you might have to wait a few seconds for the function to return the model object. If you run this code yourself you will see multiple warning messages related to the non-processing of the data previous to the exercise (not necessary for this simple example.) If you look closely, you will see that the function chose a Stochastic Gradient Boosting model, 2102 samples and 10 predictors. Mind you, there is a difference between observations in the training set and the final boosting model since it has resampled from our training set with bootstrap (25 reps.) The output says the summary of sample sizes is 2102, so we will keep that in mind when we try to cross-validate and test the model.
Testing the Model
Remember boosting resampled the training data set, so now it has fewer observations than in the original. Thus it is hard to cross-validate with the same data (length of vectors are not the same!) What we will do now is use the testing data to plot real wage data from the test set against the wage prediction from our model using the test data. These are numerical outcomes, a little harder to see on a confusion matrix but more visible in a plot.
qplot(y = predict(modFit, testing), x = wage, data = testing, ylab = "Prediction of Wage", xlab = "Wage")
If you look at the plot, our model seems to capture quite well those lower-bound wages, but there is a group of higher-wages that seem to fall out of our prediction capacity. We can see a quick rundown of our wage prediction ranges and real wages using the cut function.
While the real wages vary from 19.8 to 319.0, our prediction only ranges from 61.1 to 169.0. This is concentrated in the second and third subsets of real wages.
Conclusion
Despite having some problem with higher salaries, we clearly saw from the plot a good amount of prediction power between real wages and estimations. What is clear is the power of boosting taking rather weak predictors and incrementing their capacity through resampling for much more accurate prediction power.