Desde el comienzo Google fue un pionero en el uso de metodologías de machine learning para recopilar, ordenar y extraer sentido de las grandes cantidades de datos que generan. Trabajar para Google es una de las posiciones más buscadas en el mundo. Como una de las empresas más poderosas del globo, se dan el gusto de emplear lo mejor de lo mejor en todos los campos. Por ejemplo, cuando decidieron implementar el uso de Python como tercer lenguaje de programación (solo usaban C y Java hasta entonces) contrataron a Guido Van Rossum, ¡el dictador benévolo de por vida y creador de Python! Obviamente, tienen algunos de los mejores cerebros del mundo trabajando en cualquier cosa que tenga que ver con data.
Ahora bien, no todo el mundo en Google es un Data Scientist, y muchas veces un ingeniero querrá utilizar en su programa un poco de machine learning, no mucho, y seguir adelante con otros temas. Para tal fin Google tiene un programa llamada el Google Machine Learning Crash Course, un curso rápido para aprender aprendizaje automatizado, lo necesario para implementarlo sin destinar años de estudios.
En este blog, analizamos qué tan efectivo es el programa.

Los Temas de Hoy
Los temas de hoy son cinco:
- ¿Qué es exactamente el Google Machine Learning Crash Course?
- ¿Cómo funciona y cuantas materias son?
- ¿Quiénes son los profesores?
- ¿Cuánto cuesta? Y finalmente,
- ¿Vale la pena?
Qué es el Google Machine Learning Crash Course
El Google Machine Learning Crash Course es un curso rápido para aprender aprendizaje automatizado de acuerdo con el estilo de Google. Esto es muy importante, ya que no es un curso de ciencia de datos, ni de estadística. Tampoco está diseñado para mi o para ti, sino para los ingenieros de Google que están acostumbrados al lenguaje de Google y la manera de trabajar de Google. En inglés, crash course es un curso rápido y de emergencia, algo para transformar a un novato en un operador de una disciplina en el menor tiempo posible. La idea principal del curso es tomar ingenieros que saben mucho de programación, y que quieren implementar un poco de código de aprendizaje automatizado en sus programas, por ejemplo, para un sistema de recomendación o un algoritmo de clasificación. Esto pesa mucho en los materiales finales, ya que nunca se alejan mucho del propósito en mente.
Cómo Funciona y Cuántas Materias Son
No puedo hablar de materias, pero si puedo hablar de temas. Todo el curso convive en un sitio web manejado por Google, donde ahora se agregaron otros cursos adicionales y complementarios de Preparación de Datos, Clustering, Problem Framing, etc. Cada tema incluye una sección de videos producidos por el staff de Google explicando la teoría, y amplias páginas de teoría adicional para los que quieren tomar notas.
“Siendo el nerd que soy, comencé el curso manteniendo notas prolijas. Al comienzo pensé que estaba arruinando un cuaderno nuevo, pero ahora me doy cuenta de que quizás no me alcance para cuando haya terminado los cursos adicionales.”
Nota del Editor
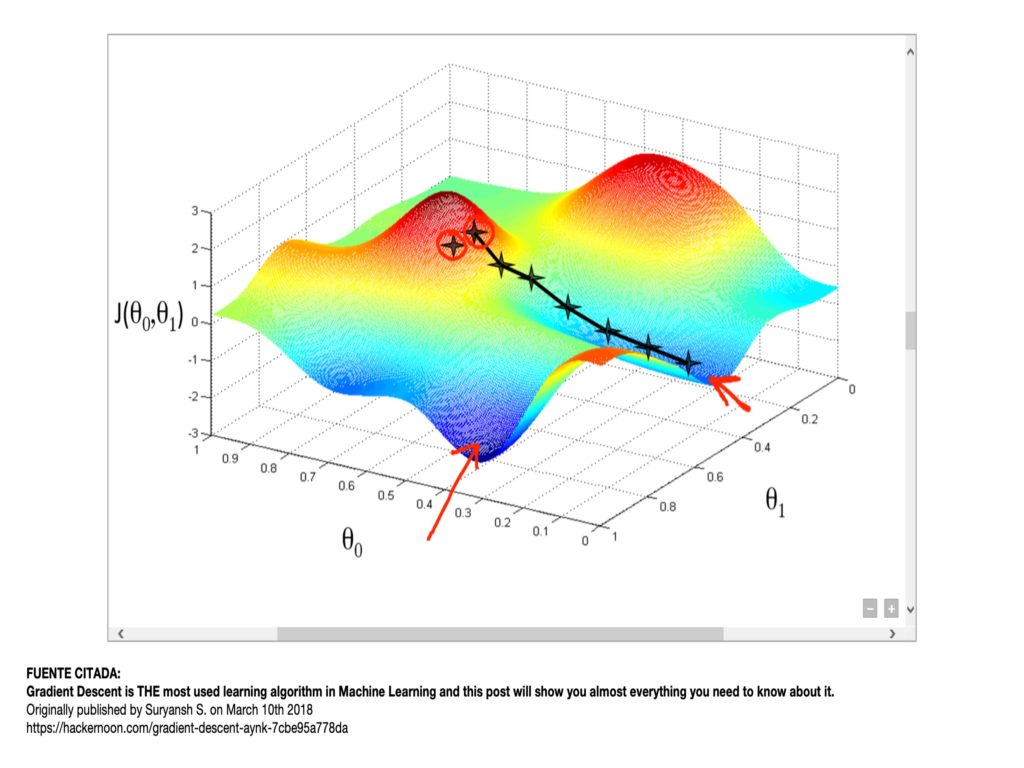
El curso comienza con los prerrequisitos de como plantear un problema de aprendizaje automatizado, que debe ser un reto para los ingenieros que salta de AGILE y SCRUM al método científico. Luego comienza desde el punto focal de todo lo que hace Google: Gradient Descent.
Hagamos un alto. El descenso de gradiente es una técnica sofisticada de minimizar una función con una o más dimensiones, ajustando los pesos de sus clasificadores que por lo general se encuentran en forma de tensores. Cuando el problema tiene más de dos dimensiones, la función puede tener más de un punto bajo que haga difícil que gradient descent ubique el mínimo. Google se apoya mucho en su librería de TensorFlow para desdoblar los hiperplanos hasta llegar a un punto donde la función se mantiene y un problema que no parece lineal se resuelve con un discriminante lineal.
A partir de aquí, la teoría avanza explicando como aplicar tensores a la resolución de problemas lineales, que es una función de pérdida, como aplicar generalización, y el uso de juegos de datos de entrenamiento, validación y test.
“Tengo que confesar que, en esto, Google tiene la explicación más sencilla de CROSS VALIDATION. Quizás porque es practica sin tanta teoría.”
Nota del Editor
Para explicar resolución de problemas sin solución lineal aparente, el curso introduce el concepto de FEATURE CROSSES. Luego sale de los problemas de resolución lineal a otros más avanzados y toca la teoría y práctica de regresión logística, clasificadores, redes neuronales, y embeddings.
No hay muchos exámenes o pruebas, pero con cada tema mayor se incluye un ejercicio completo de entrenamiento de datos y creación de un modelo final en Python. Para tal fin Google usa el sistema de Google Colaboration, que por lo que entiendo es la implementación de Google de Jupyter Notebooks pero con 1,000 veces más velocidad. Todos los problemas se resuelven usando TensorFlow, redes neuronales, y tensores.
De hecho, otro tipo de ejercicio permite resolver problemas de redes neuronales de forma visual, tratando de crear clasificadores que minimicen una función de pérdida. Al manipular todos los hiper parámetros, incluyendo el número de capas y cuantas neuronas por capa, se entiende bien el concepto de redes neuronales y qué es cada cosa (y porqué se aplica…)
Los Profesores
Todos los videos los explican varios de los ingenieros de Google que se turnan con los temas. Sin ser profesores profesionales, se notan que todos son genios, que todos explican los temas muy bien, pero que a la vez ninguno entra profundo en las lecturas. Ningún video se pasa de diez minutos.
Una mención especial va para Peter Norvic, que en el 2001 se unió a Google como Director de Machine Learning, ¡antes que nadie hablara de machine learning!
El Costo del Programa
La buena noticia, el curso es totalmente gratis. Para la cantidad de cosas que se aprende y la teoría detrás, es imposible no decir que es espectacular.
Finalmente, ¿Vale la Pena?
Un curso de Google de Machine Learning gratis lleno de contenidos y me preguntan si vale la pena? ¡Por supuesto que vale la pena! En mi caso especial, es increíble la cantidad de temas que no me habían quedado claros en otros cursos que se explicaban en tres minutos en este curso. Cosas como cross validation, gradient descent, la importancia de la función de pérdida, y la ingeniería de los cruces de aprendices (feature cross en inglés). Solo por eso vale la pena.
Habiendo dicho esto, hay algunos puntos que debo aclarar.
- No es un curso de machine learning, es un curso de TensorFlow: todos los problemas, ya sea de regresión, clasificación, recomendación, todos se resuelven con redes neuronales en TensorFlow. Esto no es malo, ya que aprender TensorFlow y redes neuronales es muy valioso. Sin embargo, no es un curso para empezar o tomarlo solo. Me parece mejor comenzar con regresión lineal, regresión multivariable, y después ver los temas comunes como arboles de decisión y clasificación, K-Means, Random Forest, series de tiempo, etc.
- No es un curso de TensorFlow, es un curso rápido de machine learning: no me contradigo. Aprender TensorFlow lleva tiempo, el manual en línea es gigante, totalmente gigante. Y por muchos ejemplos que se incluyan en los apuntes de Colab, lo que se enseña es la punta del iceberg, lo mínimo necesario para que un programa funcione. Aprender TensorFlow bien involucra horas largas de leer, estudiar y programar.
- No es un curso de programación: Hay que saber Python, y no cualquier Python sino el Python 3.0 con todas las librerías modernas que le gusta a Google. Si, lo admito, yo uso la versión 2.7 todavía. Pero si alguien llega hasta aquí y no sabe Python, no se si vale la pena seguir hasta que no se tenga un buen control del lenguaje.
- Las librerías de TensorFlow están desactualizadas: los ejemplos en Colab se aseguran de importar la versión correcta de TensorFlow para que el código funcione. Pero las librerías nuevas de TensorFlow ya cambiaron, y lo que debió ser un ajuste mínimo en las llamadas a las funciones para probar los programas localmente se convirtió en una pelea con bibliotecas depreciadas y poco apoyo para hacer los cambios. Uno debe tener mucha paciencia con los ejemplos y hacerlos en Colab, o tomarse el tiempo para reescribir todo de nuevo y que funcione…
Consideraciones Finales
Cuando busqué otros videos de YouTube sobre el curso, me sorprendió que todos lo describen como algo rápido, para terminar en una hora o menos. No se si seré yo, pero a mí me tomó cuatro semanas y cerca de cuarenta páginas de apuntes (y sin mentir, cerca de 72 horas de estudio). Esto sin contar los cursos complementarios y la necesidad de buscar temas adicionales. Por ejemplo, TensorFlow parece al principio un simple proceso de tensores, matrices que ajustan pesos de una ecuación para minimizar la función de pérdida. Pero no fue hasta que por buscar de más encontré una explicación de Deep Neural Networks donde habla de como se desdoblan los hiperplanos hasta encontrar una transformación donde la función es continua y se puede resolver con gradient descent ya que es derivable. Aquí entra el concepto de homomorfismos y como las funciones con propiedades biyectivas continúan siendo continuas y derivables en otros planos. La matemática se pone complicada ya en este punto, salimos de la estadística que es mi zona de confort para entrar en el cálculo. Pero es cuando a uno el cerebro le hace clic y entiende que TensorFlow es más, que la parte del Flow es la increíble transformación visual de los planos donde funciones que en dos dimensiones parecen nudos o manifolds tiene continuidad y no se tocan en múltiples dimensiones o hiperplanos.
Yo recomiendo altamente este curso, pero no lo hagan de primera instancia, sino que atáquenlo cuando tengan una buena base de que significa el entrenamiento de datos, y como se hace en instancias más sencillas para ir incrementando el nivel de especialización.